
- Title
-
On the objectivity, reliability, and validity of deep learning enabled bioimage analyses
- Authors
- Segebarth, D., Griebel, M., Stein, N., R von Collenberg, C., Martin, C., Fiedler, D., Comeras, L.B., Sah, A., Schoeffler, V., Lüffe, T., Dürr, A., Gupta, R., Sasi, M., Lillesaar, C., Lange, M.D., Tasan, R.O., Singewald, N., Pape, H.C., Flath, C.M., Blum, R.
- Source
- Full text @ Elife
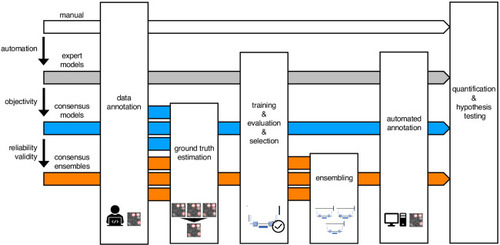
Schematic illustration of bioimage analysis strategies and corresponding hypotheses. Four bioimage analysis strategies are depicted. Manual (white) refers to manual, heuristic fluorescent feature annotation by a human expert. The three DL-based strategies for automatized fluorescent feature annotation are based on expert models (gray), consensus models (blue) and consensus ensembles (orange). For all DL-based strategies, a representative subset of microscopy images is annotated by human experts. Here, we depict labels of cFOS-positive nuclei and the corresponding annotations (pink). These annotations are used in either individual training datasets (gray: expert models) or pooled in a single training dataset by means of ground truth estimation from the expert annotations (blue: consensus models, orange: consensus ensembles). Next, deep learning models are trained on the training dataset and evaluated on a holdout validation dataset. Subsequently, the predictions of individual models (gray and blue) or model ensembles (orange) are used to compute binary segmentation masks for the entire bioimage dataset. Based on these fluorescent feature segmentations, quantification and statistical analyses are performed. The expert model strategy enables the automation of a manual analysis. To mitigate the bias from subjective feature annotations in the expert model strategy, we introduce the consensus model strategy. Finally, the consensus ensembles alleviate the random effects in the training procedure and seek to ensure reliability and eventually, validity. |
The U-Net architecture was adapted from |

( |
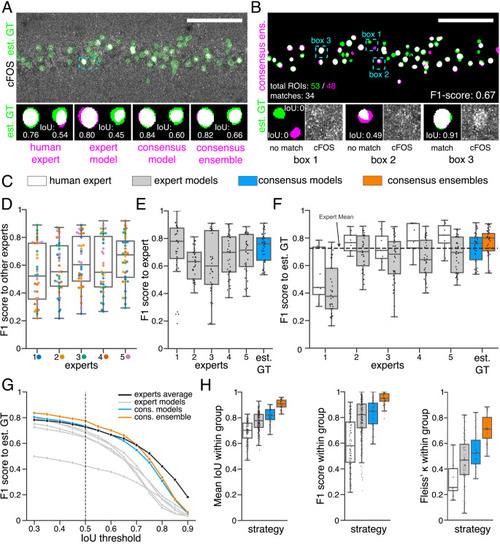
(A) Representative example of IoU MIoU calculations on a field of view (FOV) in a bioimage. Image raw data show the labeling of cFOS in a maximum intensity projection image of the CA1 region in the hippocampus (brightness and contrast enhanced). The similarity of estimated ground truth (est. GT) annotations (green), derived from the annotations of five expert neuroscientists, are compared to those of one human expert, an expert model, a consensus model, and a consensus ensemble (magenta, respectively). IoU results of two ROIs are shown in detail for each comparison (magnification of cyan box). Scale bar: 100 µm. (B) F1 score MF1 score calculations on the same FOV as shown in (A). The est. GT annotations (green; 53 ROIs) are compared to those of a consensus ensemble (magenta; 48 ROIs). IoU-based matching of ROIs at an IoU-threshold of t=0.5 is depicted in three magnified subregions of the image (cyan boxes 1-3). Scale bar: 100 µm. (C–H) All comparisons are performed exclusively on a separate image test set which was withheld from model training and validation. (C) Color coding refers to the individual strategies, as introduced in Figure 1: white: manual approach, gray: expert models, blue: consensus models, orange: consensus ensembles. (D) MF1 score between individual manual expert annotations and their overall reliability of agreement given as the mean of Fleiss‘ κ. (E) MF1 score between annotations predicted by individual models and the annotations of the respective expert (or est. GT), whose annotations were used for training. Nmodels per expert = 4. (F) MF1 score between manual expert annotations, the respective expert models, consensus models, and consensus ensembles compared to the est. GT as reference. A horizontal line denotes human expert average. Nmodels = 4, Nensembles = 4. (G) Means of MF1 score of the individual DL-based strategies and of the human expert average compared to the est. GT plotted for different IoU matching thresholds t. A dashed line indicates the default threshold t=0.5. Nmodels = 4, Nensembles = 4. (H) Annotation reliability of the individual strategies assessed as the similarities between annotations within the respective strategy. We calculated M̄IoU, MF1 score and Fleiss‘ κ. Nexperts = 5, Nmodels = 4, Nensembles = 4. |
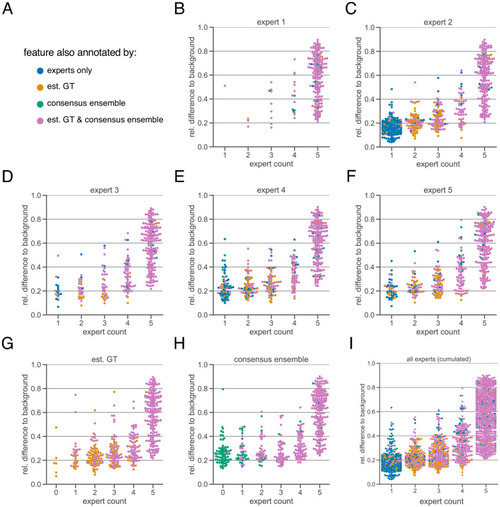
The subjectivity analysis depicts the relationship between the relative intensity difference of a florescent feature (ROI) to the background and the annotation count of human experts. A visual interpretation indicates that the annotation probability of a ROI is positively correlated with its relative relative intensity. The relative intensity difference is calculated as µinner–µouter/µinner where µinner is the mean signal intensity of the ROIs and µouter the mean signal intensity of its nearby outer area. We considered matching ROIs at an IoU threshold of t=0.5. The expert in the title of the respective plot was used to create the region proposals of the ROIs, that is, the annotations served as origin for the other pairwise comparisons. ( |
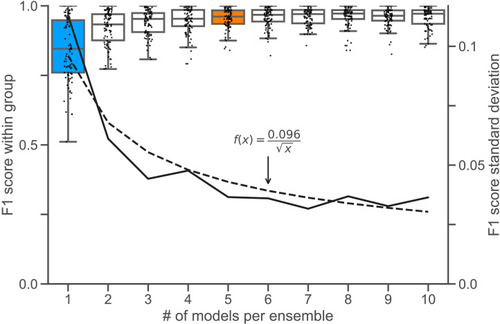
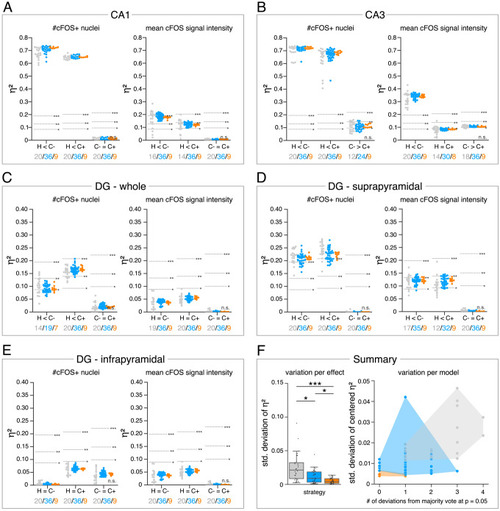
To determine an appropriate size for the consensus |
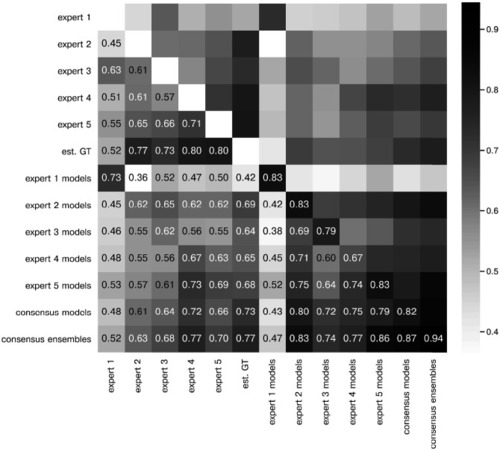
The heatmap shows the mean of MF1 score at a matching IoU-threshold of t=0.5 for the image feature annotations of the indicated experts. Segmentation masks of the five human experts (Nexpert = 1 per expert), the estimated ground-truth (Nest. GT = 1), the respective expert models, the consensus models, and the consensus ensembles (Nmodels = 4 per model or ensemble) are compared. The diagonal values show the inter-model reliability (no data available for the human experts who only annotated the images once). The consensus ensembles show the highest reliability (0.94) and perform on par with human experts compared to the est. GT (0.77). Both expert 1 and the corresponding expert 1 models show overall low similarities to other experts and expert models, while sharing a high similarity to each other (0.73). |
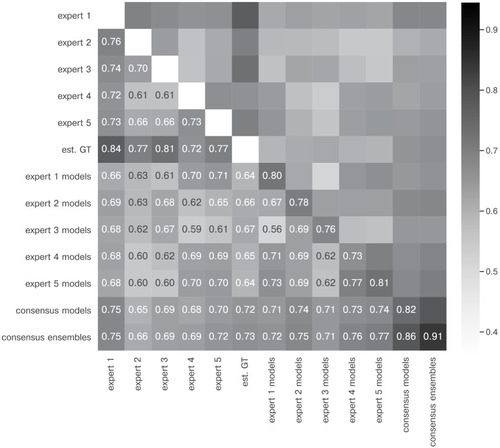
The heatmap shows the mean of M̄IoU for the image feature annotations of the indicated experts. Segmentation masks of the five human experts (Nexpert = 1 per expert), the estimated ground-truth (Nest. GT = 1), the respective expert models, the consensus models, and the consensus ensembles (Nmodels = 4 per model or ensemble) are compared. The diagonal values show the inter-model reliability (no data available for the human experts who only annotated the images once). Again, consensus ensembles show highest reliability (0.91). Est. GT annotations are directly derived from manual expert annotations, which renders this comparison favorable. |
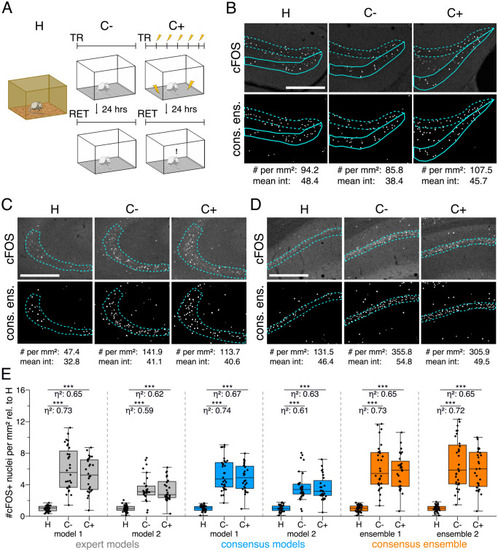
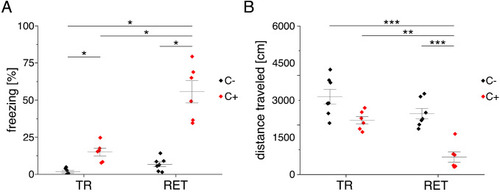
The figure introduces how three DL-based strategies are applied for annotation of a representative fluorescent label, here cFOS, in a representative image data set. Raw image data show behavior-related changes in the abundance and distribution of the protein cFOS in the dorsal hippocampus, a brain center for encoding of context-dependent memory. (A) Three experimental groups were investigated: Mice kept in their homecage (H), mice that were trained to a context, but did not experience an electric foot shock (C-) and mice exposed to five foot shocks in the training context (C+). 24 hr after the initial training (TR), mice were re-exposed to the training context for memory retrieval (RET). Memory retrieval induces changes in cFOS levels. (B–D) Brightness and contrast enhanced maximum intensity projections showing cFOS fluorescent labels of the three experimental groups (H, C-, C+) with representative annotations of a consensus ensemble, for each hippocampal subregion. The annotations are used to quantify the number of cFOS-positive nuclei for each image (#) per mm2 and their mean signal intensity (mean int., in bit-values) within the corresponding image region of interest, here the neuronal layers in the hippocampus (outlined in cyan). In B: granule cell layer (supra- and infrapyramidal blade), dotted line: suprapyramidal blade, solid line: infrapyramidal blade. In C: pyramidal cell layer of CA3; in D: pyramidal cell layer in CA1. Scale bars: 200 µm. (E) Analyses of cFOS-positive nuclei per mm2, representatively shown for stratum pyramidale of CA1. Corresponding effect sizes are given as η2 for each pairwise comparison. Two quantification results are shown for each strategy and were selected to represent the lowest (model 1 or ensemble 1) and highest (model 2 or ensemble 2) effect sizes (increase in cFOS) reported within each annotation strategy. Total analyses performed: Nexpert models = 20, Nconsensus models = 36, Nconsensus ensembles = 9. Number of analyzed mice (N) and images (n) per experimental condition: NH = 7, NC- = 7, NC+ = 6; nH = 36, nC- = 32, nC+ = 28. ***p<0.001 with Mann-Whitney-U test. Statistical data are available in Figure 3—source data 1. |
( |
(A–E) Single data points represent the calculated effect sizes for each pairwise comparison of all individual bioimage analyses for each DL-based strategy (gray: expert models, blue: consensus models, orange: consensus ensembles) in indicated hippocampal subregions. Three horizontal lines separate four significance intervals (n.s.: not significant, *: 0.05 ≥ p>0.01, **: 0.01 ≥ p>0.001, ***: p ≤ 0.001 after Bonferroni correction for multiple comparisons). The quantity of analyses of each strategy that report the respective statistical result of the indicated pairwise comparison (effect, x-axis) at a level of p ≤ 0.05 are given below each pairwise comparison in the corresponding color coding. In total, we performed all analyses with: Nexpert models = 20, Nconsensus models = 36, Nconsensus ensembles = 9. Number of analyzed mice (N) for all analyzed subregions: NH = 7, NC- = 7, NC+ = 6. Numbers of analyzed images (n) are given for each analyzed subregion. Source files including source data and statistical data are available in Figure 4—source data 1. (A) Analyses of cFOS-positive nuclei in stratum pyramidale of CA1. n |
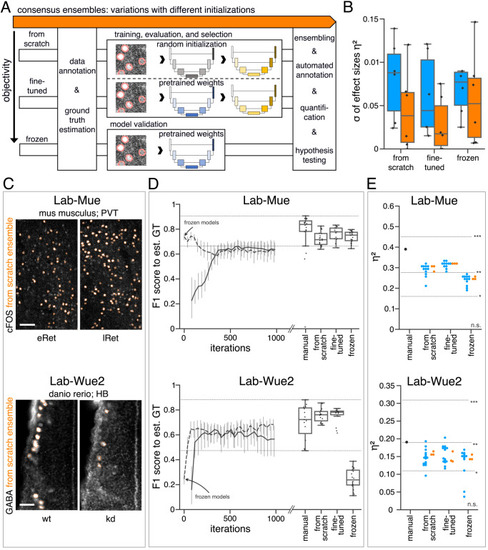
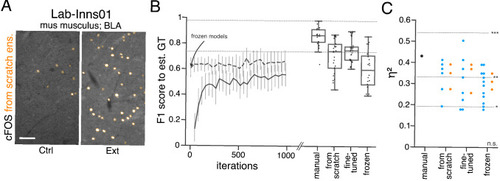
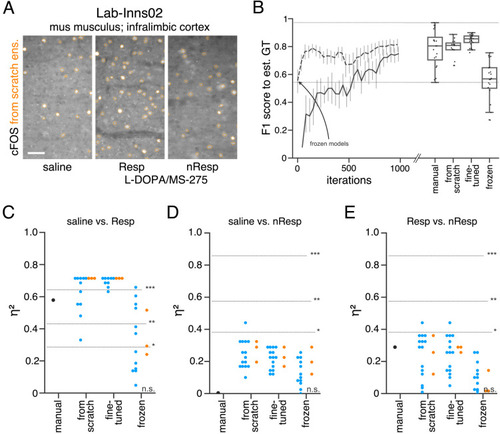
(A) Schematic overview depicting three initialization variants for creating consensus ensembles on new datasets. Data annotation by multiple human experts and subsequent ground truth estimation are required for all three initialization variants. In the from scratch variant, a U-Net model with random initialized weights is trained on pairs of microscopy images and estimated ground truth annotations. This variant was used to create consensus ensembles for the initial Lab-Wue1 dataset. Alternatively, the same training dataset can be used to adapt a U-Net model with pretrained weights by means of transfer-learning (fine-tuned). In both variants, models are evaluated and selected on base of a validation set after model training. In a third variant, U-Net models with pretrained weights can be evaluated directly on a validation dataset, without further training (frozen). In all three variants, consensus ensembles of the respective models are then used for bioimage analysis. (B) Overall reliability of bioimage analysis results of each variant assessed as variation per effect. In all three strategies, consensus ensembles (orange) showed lower standard deviations than consensus models (blue). The frozen results need to be considered with caution as they are based on models that did not meet the selection criterion (see Figure 5—source data 3). Npairwise comparisons = 6; Nconsensus models = 15, and Nconsensus ensembles = 3 for each variant. (C–E) Detailed comparison of the two external datasets with highest (Lab-Mue) and lowest (Lab-Wue2) similarity to Lab-Wue1. (C) Representative microscopy images. Orange: representative annotations of a lab-specific from scratch consensus ensemble. PVT: para-ventricular nucleus of thalamus, eRet: early retrieval, lRet: late retrieval, HB: hindbrain, wt: wildtype, kd: gad1b knock-down. Scale bars: Lab-Mue 100 µm and Lab-Wue2 6 µm. (D) Mean MF1 score of from scratch (solid line) and fine-tuned (dashed line) consensus models on the validation dataset over the course of training (iterations). Mean MF1 score of frozen consensus models are indicated with arrows. Box plots show the MF1 score among the annotations of human experts as reference and the mean MF1 score of selected consensus models. Two dotted horizontal lines mark the whisker ends of the MF1 score among the human expert annotations. (E) Effect sizes of all individual bioimage analyses (black: manual experts, blue: consensus models, orange: consensus ensembles). Three horizontal lines separate the significance intervals (n.s.: not significant, *: 0.05≥ p>0.01, **0.01≥ p>0.001, ***p ≤ 0.001 with Mann-Whitney-U tests). Lab-Mue: Nconsensus ensembles = 3 for all initialization variants; Nfrom scratch/fine-tuned consensus models = 12 (for each ensemble, 4/5 trained models per ensemble met the selection criterion), Nfrozen consensus models = 12 (for each ensemble, 4/4 models per ensemble did not meet the selection criterion). NeRet = 4, NlRet = 4; neRet = 12, nlRet = 11. Lab-Wue2: Nconsensus ensembles = 3 for each initialization variant; Nfrom scratch/fine-tuned consensus models = 15 (for each ensemble, 5/5 trained models per ensemble met the selection criterion), Nfrozen consensus models = 12 (for each ensemble, 4/4 models per ensemble did not meet the selection criterion). Nwt = 5, Nkd = 4, nwt = 20, nkd = 15. Source files of all statistical analyses (including Figure 5—figure supplement 2 and Figure 5—figure supplement 1) are available in Figure 5—source data 1. Information on all bioimage datasets (e.g. the number of images, image resolution, imaging techniques, etc.) are available in Figure 5—source data 2. Source files on model performance and selection are available in (Figure 5—source data 3). |
( |
( |
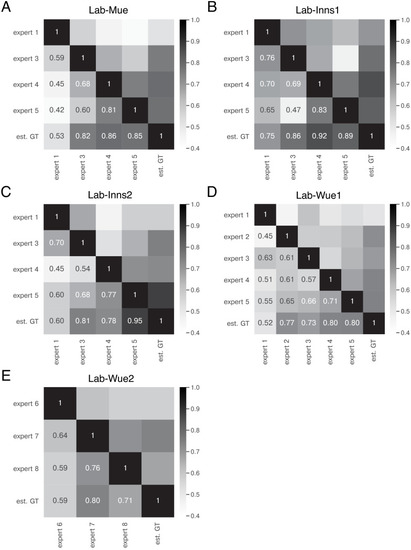
The heatmaps show the mean of |
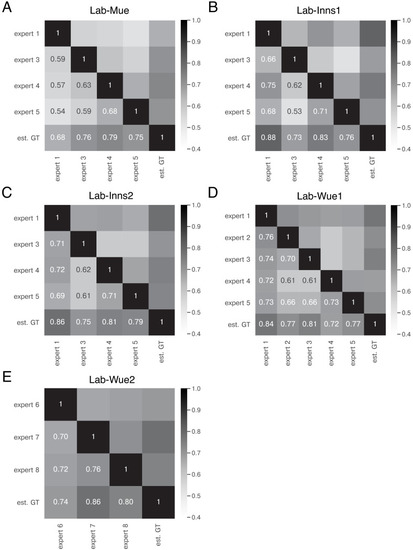
The heatmaps show the mean of |
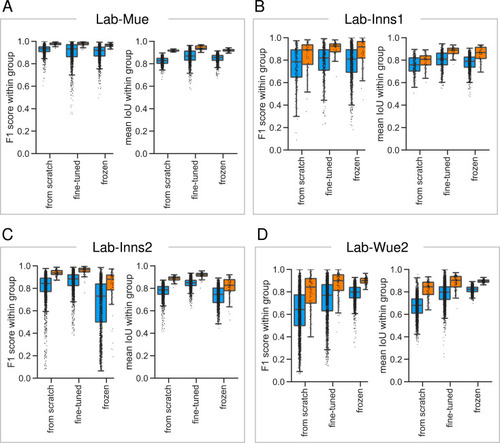
To asses the reliability and reproducibility of the |