
Figure 2—figure supplement 3.
- ID
- ZDB-IMAGE-201209-39
- Publication
- Segebarth et al., 2020 - On the objectivity, reliability, and validity of deep learning enabled bioimage analyses
- All Figures
- Figures for Segebarth et al., 2020
|
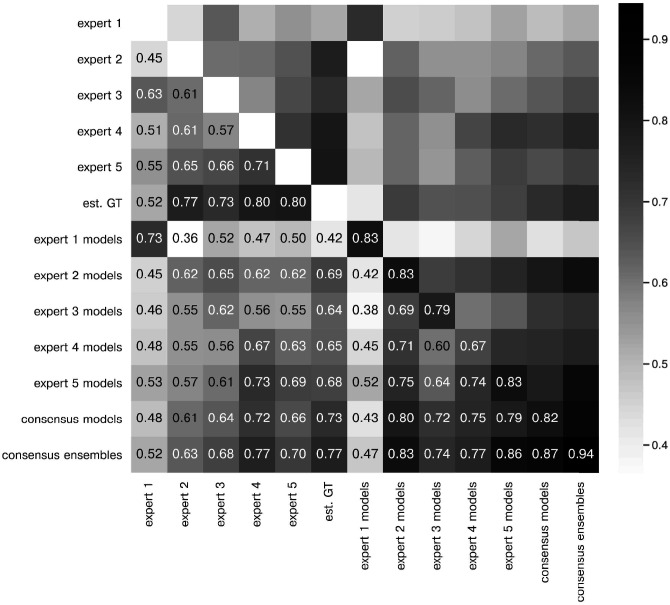
Figure 2—figure supplement 3. The heatmap shows the mean of MF1 score at a matching IoU-threshold of t=0.5 for the image feature annotations of the indicated experts. Segmentation masks of the five human experts (Nexpert = 1 per expert), the estimated ground-truth (Nest. GT = 1), the respective expert models, the consensus models, and the consensus ensembles (Nmodels = 4 per model or ensemble) are compared. The diagonal values show the inter-model reliability (no data available for the human experts who only annotated the images once). The consensus ensembles show the highest reliability (0.94) and perform on par with human experts compared to the est. GT (0.77). Both expert 1 and the corresponding expert 1 models show overall low similarities to other experts and expert models, while sharing a high similarity to each other (0.73).