
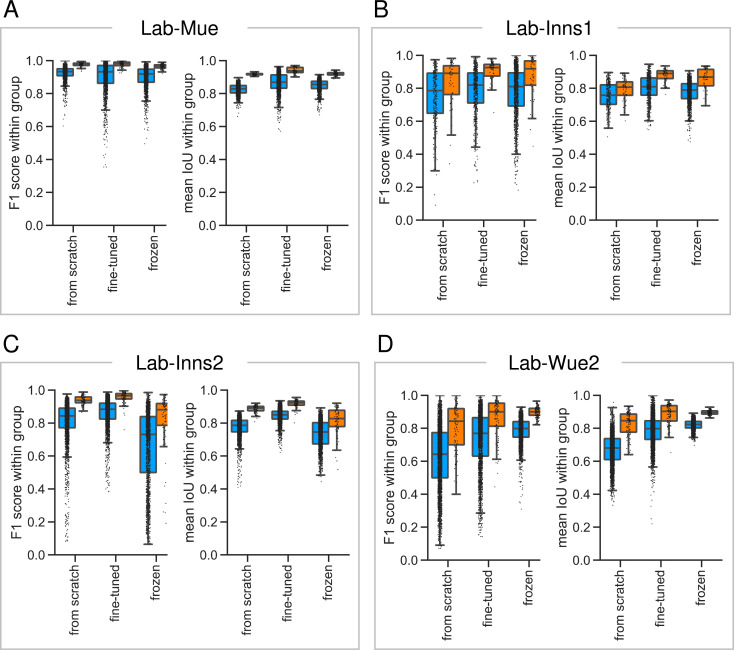
Figure 5—figure supplement 5.
- ID
- ZDB-IMAGE-201209-44
- Publication
- Segebarth et al., 2020 - On the objectivity, reliability, and validity of deep learning enabled bioimage analyses
- All Figures
- Figures for Segebarth et al., 2020
|
Figure 5—figure supplement 5.
To asses the reliability and reproducibility of the